AI 绘画的底层逻辑:从概率预测到多模态引导
AI 绘画的核心并非“创作”,而是基于深度学习模型的“概率预测”。它通过将人类语言的语义空间映射到海量图像的像素分布,在去噪过程中寻找最符合概率分布的像素组合。到 2026 年 3 月,该技术已从简单的文本出图演进为像素级控制与实时协作,在商业设计、游戏开发等领域重构了生产关系。
目前,单纯的文本驱动正被“多模态引导”取代。由于模型底层逻辑是潜空间(Latent Space)的变换,出图质量取决于对该空间的引导能力,而非文字的优美程度。通过草图、深度图或语义分割图结合文本,创作者才能实现对画面构图的绝对掌控。
AI 生成的三个阶段与不确定性
AI 生成流程分为三个阶段:编码(文字转向量)、扩散(迭代剔除噪声)与解码(还原可见图像)。

这种机制导致 AI 在处理复杂逻辑(如手指数量、文字拼写)时存在天然的不确定性。虽然 2026 年引入的精细化注意力机制改善了这一现状,但逻辑断裂的问题依然存在,无法完全消除。
实操指南:构建精准的“控制流”工作法
对于实践者,建议采用“控制流”工作法。以 Stable Diffusion 及其 2026 年迭代版本为例,具体实操步骤如下:
第一步:构建结构化提示词矩阵
提示词应视为一组权重标签,遵循“主体 + 环境 + 材质/光影 + 艺术风格 + 技术参数”的结构。

(high quality:1.2))增强特定元素。
4. 负向排除: 配置 Negative Prompt(如 (worst quality, low quality:1.4), deformed iris, extra fingers)排除干扰项。
第二步:通过 ControlNet 实现像素级控制
文字无法精准定位物体位置,此时需引入 ControlNet 附加网络以实现空间引导。
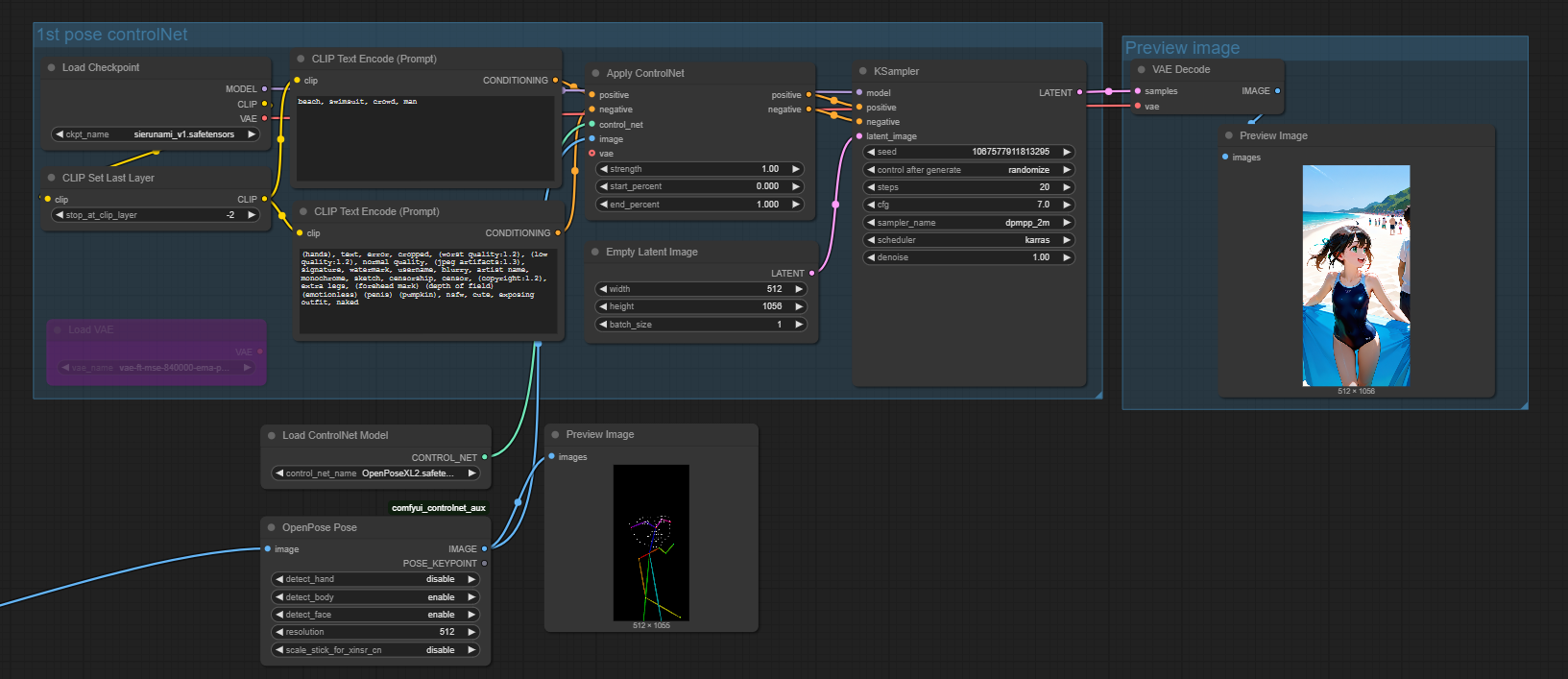
第三步:局部重绘(Inpainting)与精修
商业可用图像必须经过局部重绘,以解决 AI 生成中的细节瑕疵。

工具生态与行业边界
工具选择上,市场呈现分层态势。

| 工具名称 | 核心优势 | 适用人群 | 硬件/成本要求 |
|---|---|---|---|
| Midjourney v7 | 光影摄影级、极高审美 | 创意人员、高效出图者 | 订阅制 (30-60$/月) |
| Stable Diffusion | 开源生态、Lora 微调、精准控制 | 专业设计师、技术画师 | 显存 16GB+ (本地运行) |
| Adobe Firefly | 版权合规、工作流集成 | 商业企业、广告公司 | Adobe 订阅 |
然而,AI 绘画存在明显的边界条件。在需要极高逻辑精度的场景(如电路图、建筑工程图)中,AI 常出现逻辑断裂。在艺术表达上,AI 只能模拟已知风格(如“像梵高”),无法产生基于感官体验的全新流派。
如何解决商业项目中的版权风险?
建议优先选择 Adobe Firefly 等基于授权数据集的模型,或通过自有版权数据集训练专属的 Lora 模型,以确保法律层面的安全性。
AI 绘画是否会导致设计师丧失核心竞争力?
过度依赖 AI 确实可能导致手绘草图能力的退化。因此,建议设计师将重点从单纯的“执行力”转向提升“审美策展力”与“逻辑构建力”,将 AI 视为实现视觉语言的工具而非替代品。
面对 2026 年的 AI 格局,个人创作者该如何建立壁垒?
可以通过建立私人 Lora 风格库,将真实的摄影作品或原创手绘喂给模型,构建一套独有的、不可轻易被通用模型复制的视觉语言系统。
总结:从工具使用者进化为视觉策展人
在 AI 绘画技术日趋成熟的今天,真正的竞争点已不再是掌握多少个提示词技巧,而是对图像质量的判断力以及对复杂视觉逻辑的拆解能力。通过将“结构化提示词 $\rightarrow$ ControlNet 引导 $\rightarrow$ 局部精修”这一套闭环工作流内化,创作者可以将 AI 从一个随机的“抽卡机”转化为一个精准的生产力引擎。